In-depth: ClickHouse vs Druid
Jan 13, 2023


- Mathew Pregasen
Contrary to what the names might suggest, ClickHouse isn’t an TikTok influencer house and Druid isn’t (just) a D&D character class – they're both modern online analytical processing (OLAP) databases designed to store and retrieve lots of data fast.
OLAP databases store data in a columnar format that is primed for aggregations, unlike online transaction processing (OLTP) ones like mySQL (see below). But, while ClickHouse and Druid solve a fundamentally similar problem, they do so via dramatically different approaches.
Products with massive volumes of data, like business intelligence tools, stock market trading books, and apps with lots of charts and graphs, can benefit from using OLAP databases.
At PostHog, we use ClickHouse to power our analytics warehouse – lovingly dubbed our Events Mansion. ClickHouse was a saving grace when our Postgres setup was grinding to a halt due to our growth.
But what about Apache Druid? An accomplished database in its own right, Druid approaches common analytical problems very differently.
In this article, we’ll explore those differences, including how they work, who uses which, and why.
Want to know more about OLAP (column-based) vs OLTP (row-based) databases? Read our guide comparing ClickHouse (OLAP) and PostgreSQL, the most popular open-source OLTP database.
Architecture
Have you ever been asked if you'd prefer to fight a hundred duck-sized horses or one horse-sized duck?
Well, Druid is the former and ClickHouse is the latter. If that analogy doesn't work, consider this instead:
ClickHouse is like a lakefront mansion. You keep the house, polish the interior, and extend it with extra wings when the need arises.
Druid is a master-plan suburban community where each house is interconnected by roads and (in some cases) a shared canal because... canals are nice?
ClickHouse is about keeping every component of the database tightly woven via a single binary executable; Druid’s architecture is modular, configurable, and consequently more complicated.
How ClickHouse works
ClickHouse's cornerstone principle is that ClickHouse should do the work for you. ClickHouse automatically ingests, compresses, and creates materialized views of data with minimal set-up required from the user.
Here's what that looks like in practice:
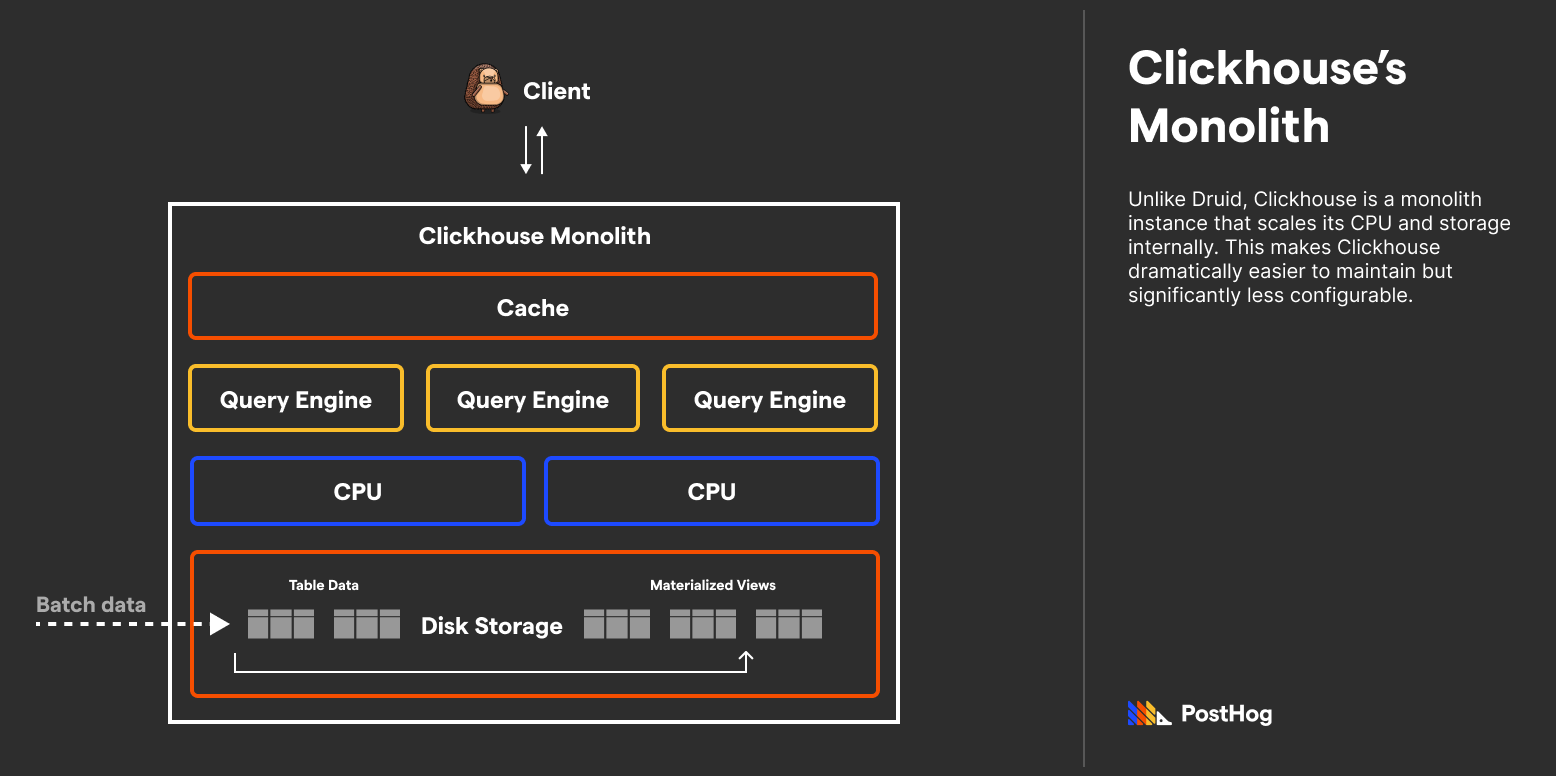
What is a materialized view? A materialized view, unlike a normal view, is a separate table of data generated at a specific time from the base tables. This makes running queries on data in materialized views more efficient (if set up correctly). Materialized views don't need to be re-queried before being queried from, unlike normal views.
While Postgres, a row-based OLTP database, supports materialized views, they aren’t good for dynamic data since refreshing them is expensive. ClickHouse uniquely can efficiently update materialized views upon new data within a delay threshold.
Most databases achieve speed by caching calculated results after an initial slow query. ClickHouse’s materialized views do the heavy-lifting ahead of time, and are constantly updating so that they’re never too out-of-date. This is a happy medium for a lot of data-driven applications, and contributes to ClickHouse's reputation for extremely fast query performance on large datasets.
Apache Zookeeper: ClickHouse does admit a flaw in its single executable promise. If the database is expected to have replicas, it requires Apache Zookeeper to manage the redundancies. However, this is a rather thin layer atop of a ClickHouse cluster, and a problem addressed by the introduction of ClickHouse Keeper.
Caches: ClickHouse boasts different types of caches for discrete optimizations. ClickHouse’s MergeTree table family has unique caches that improve data fetches.
Dedicated Engines: ClickHouse boasts a number of dedicated engines that utilize parallel calculations to expedite data crunching. For instance, the SummingMergeTree Engine is able to sum values throughout a database significantly faster than a linear analog. This makes Clickhouse apt for analytics products that need to do a lot of algebraic math across vast datasets.
How Druid works
Druid is all about modularity. Druid separates the query, data, and storage nodes into three separate machines. Does that mean there is extra latency? By the Druid’s team’s own concession, an unapologetic yes. Druid’s argument is that intra-database latency is justifiable for the customizable and precision benefits of its approach.
Let’s take a look at a Druid setup:
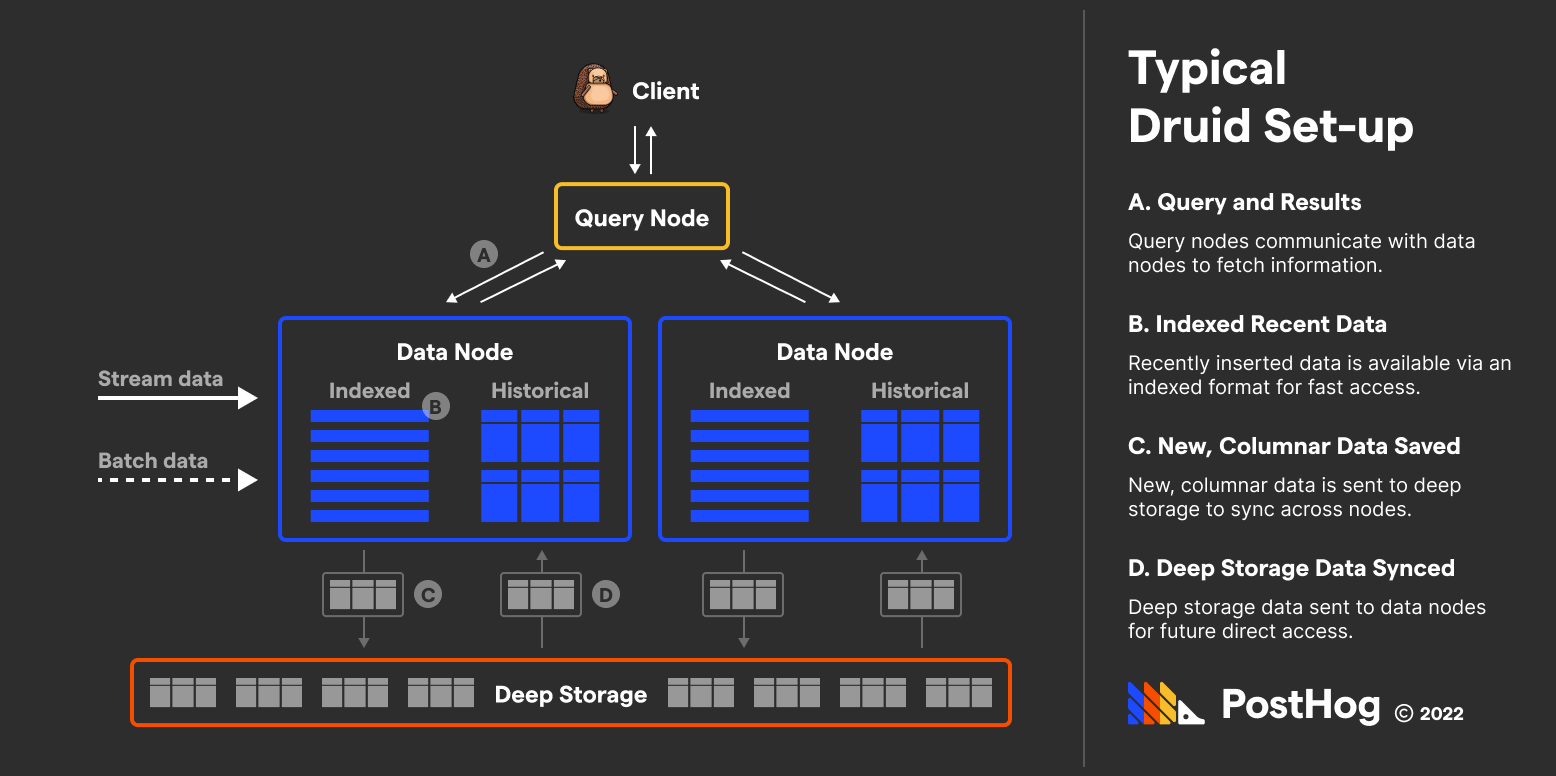
Druid is built for massive applications with unique data streaming needs. For instance, imagine an application that needs to take the last stock trade into account before returning a value.
ClickHouse would stumble with this – ClickHouse doesn’t guarantee newly ingested data is included in the next query result. Druid, meanwhile, does – efficiently, too, by storing the newly streamed data temporarily in the data nodes whilst simultaneously packing and shipping it off to deep storage.
Remember that analogy between the mansion and master-plan community? For Druid, the query nodes are the roads, the data nodes are the houses, and storage is the sprawling, shared lake.
Cattle vs Pets
Druid expects you to treat its nodes like cattle, constantly removing and adding nodes on a whim. You would never do that with ClickHouse instances since each ClickHouse instance likely plays a critical role in your application’s stability.
You have to treat ClickHouse more like your pet, caring about it individually and making sure it stays alive. Druid, meanwhile, expects you to utilize up to ten thousand data nodes, each which could be taken offline and maintained without impacting the application.
Of course, this means that Druid requires more maintenance work. Much more maintenance work. Not just that, but server costs, too. Druid is built for large enterprise clients with complex needs and massive financial backing to support the architecture. ClickHouse, meanwhile, is a one-size-fits-most solution; scalable, just not in the same multidimensional, multi-structural way as Druid is.
Stream data over batch data
ClickHouse, expects data to be batched – this is because ClickHouse re-renders materialized views, and prefers to do that for a collection of data, not for every arbitrary insert. But Druid has different priorities.
When stream data is ingested into Druid, it stores the stream data ephemerally in the data node while in parallel storing the same data in the storage node. This is similar to a cache, but notably makes data available in-memory before it was even fetched once.
You can consider this approach somewhat similar to the philosophy behind ClickHouse’s dynamic materialized views, however, the end deliverable is different. ClickHouse is able to calculate results that utilize the entire database minus recent data (such as an all-time average) without buffering the entire database into memory. Druid, meanwhile, is able to return the recent data extremely fast.
Caching: Druid, like ClickHouse, enables you to cache query results. Druid users can cache results of an entire query or a segment of a query.
Prioritization (Tiering): One of Druid’s hallmark features is prioritization. While Clickhouse strives to make every query hypothetically efficient, Druid allows users to prioritize queries. Mission-critical queries can force low-priority queries to pause / get delayed. This is an ideal feature for applications where the most expensive queries are the least required to be fast.
Use cases
ClickHouse and Druid strive to solve the same problem, but they have unique strengths and weaknesses that make them ideal for different use cases.
Let’s explore these factors for both.
When to use ClickHouse
As with any technical comparison, you should default to the simpler tool if you can. ClickHouse is easy to setup, doesn’t involve multi-piece architecture to maintain, and has a chest of tools for a majority of needs.
In fact, it’s less about when you should use ClickHouse and more about when you shouldn’t. Here are some reasons for why ClickHouse may not be the right solution for you:
- You cannot batch data
- You need to accurately retrieve data that was just inserted
- You need to prioritize queries and believe a certain query will be slow in ClickHouse
Of course, you can utilize ClickHouse even with these constraints if you utilize additional scaffolding architecture such as caches. While that detracts from ClickHouse’s single-monolith value prop, they are valid techniques to still use ClickHouse, especially if ClickHouse is ideal because of its:
- Specialized engines
- Simplified internal architecture
- Materialized views
Speaking from experience, if you run a billion-event product analytics platform like ours, you should use ClickHouse 😉.
When to use Druid
Druid is an ideal solution for teams that require a modular design with precision. If you need to fetch data immediately after the data was streamed, Druid is great. However, there are some key caveats that you need to be aware of:
- Druid is more complex to set up and maintain
- Druid is more expensive as it requires more machines and systems
Additionally, Druid is the best solution for applications that need real-time data reporting with precision. For instance, a stock market order-book app may utilize Druid because users expect accurate and aggregate financial data in real-time.
Which companies use ClickHouse and why?
PostHog: We switched from Postgres to Clickhouse as we scaled and never looked back. By utilizing ClickHouse’s dedicated engines and materialized views, we are able to efficiently return event data to our users with minimal overhead and support billion-event scale companies.
Ebay: Ebay switched from Druid to ClickHouse with Apache Zookeeper to dramatically reduce its server costs and simplify its backend. Originally, Ebay’s Druid setup was sprawling and complicated to maintain, racking up serious engineering costs. After switching to ClickHouse, Ebay’s overall infrastructure was reduced by a whopping 90%.
Uber: Uber moved its logging platform to ClickHouse, improving data compression and halving its infrastructure costs. Given that Uber needs to log a lot of geographical information during car rides, ClickHouse was the apt solution for streaming data.
Which companies use Druid and why?
Airbnb:* Druid enables Airbnb to analyze both historical and real-time metrics, returning data for Airbnb hosts quickly and interactively. Because Airbnb processes hundreds of transactions every minute, Druid enables them to return accurate pricing shifts efficiently.
Lyft: Probably the best example on how Druid and ClickHouse could be used interchangeably with additional architecture is Uber’s cousin’s choice in Druid. Lyft utilizes Druid, with some additional setup, to achieve similar results as Uber has.
Rovio: The makers of everyone’s favorite angry ducklings game, Rovio uses Druid to chop and pivot time-series dashboards filled with data from their millions of players.
Summary
Druid and ClickHouse both seek to handle large volumes of data at speed, but they do so in completely different ways. ClickHouse champions simplicity and a unified instance; Druid is complex but highly configurable.
While both offer enormous advantages over traditional databases for columnar data, companies should strongly consider their needs when making choice between the two.
ClickHouse pros and cons
Pros
- Low latency
- Simple to set up, can operate out of a single instance
- Materialized Views expedite aggregations at the data level
- Extremely fast query performance on large datasets
Cons
- Expects users to batch data
- Cannot return data immediately after insert
Druid pros and cons
Pros
- Highly configurable and scalable
- Can return data immediately after insert
- Has prioritization of queries built natively
Cons
- Expensive setup
- Harder to maintain
- More latency due to multiple layers
Further reading
Altinity's 2021 analysis comparing the performance and cost efficiency of ClickHouse, Druid and Rockset. Altinity, maintains a useful database of ClickHouse benchmarks in a variety of use cases.
ClickHouse's CTO, Alexey Milovidov, 2022 talk "Building for Fast".
How we turned ClickHouse into our event mansion by our own James Greenhill explores in more depth why we chose ClickHouse for PostHog. We also maintain an internal ClickHouse manual.

Subscribe to our newsletter
Product for Engineers
Join 25k+ subscribers learning how to build successful products and become better engineers.
We'll share your email with Substack